

Butuh aplikasi monitoring yang powerfull? anti downtime? dan yang utama opensource?? Akvorado jawabannya! Kali ini saya kembali dengan tool yang akan memudahkan engineer untuk monitoring flow jaringan homelab kalian yang berantakan itu. Apasih akvorado? Singkatnya, Akvorado berfungsi sebagai kolektor dan visualisasi dari netflow/ipfix dan sflow. Lalu netflow/ipfix dan sflow itu apa? Nah, mereka adalah exporter yang akan memberikan data flow ke aplikasi monitoring yang akan kita pakai kali ini.
Terus apasih yang membuatnya powerfull? Itu karena, akvorado ini menggunakan berbagai macam komponen opensource yang memang fokusnya untuk mengelola data yang banyak, misalnya Apache Kafka dan Clickhouse. Juga, satu hal lagi yang menarik menurut saya ialah pembagian kerja pada setiap komponen akvorado, yang membuat kita bisa memodifikasi struktur aplikasi sesuka kita. Kebetulan Lab lokal saya berada dibeda lokasi secara geologi, jadi bisa saya implementasikan dengan skema High Availability + Loadbalance untuk mengantisipasi mati lamput bergilir seperti kondisi saat ini hehe...
Karena saya akan memakai homelab saya sebagai bahan implementasi, mungkin akan ada beberapa bagian yang saya lewatkan untuk memangkas postingan ini. Oke lanjut ke pembahasannya.
1. lab environment
Topology
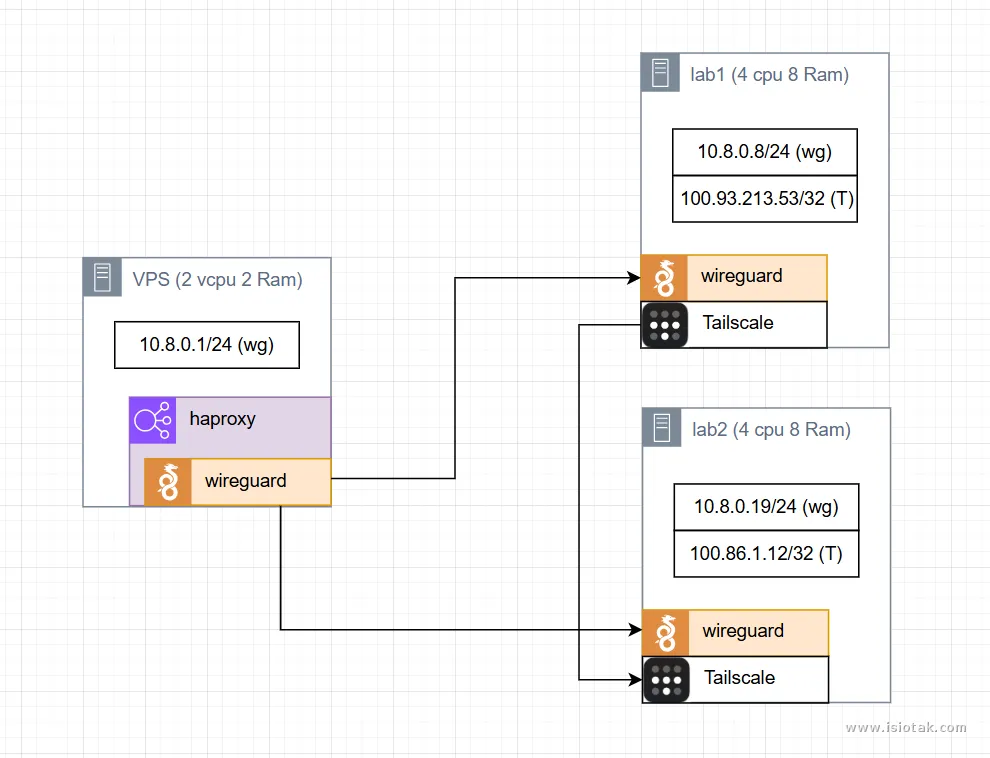
Untuk versi service yang dipakai menyesuaikan saja selama bisa terhubung satu sama lain melalui IP apapun.
vps1 (vps Indonesia) - Ubuntu 24.04 (Noble)
lab1 (kosan) - Ubuntu 24.04 (Noble)
lab2 (rumah) - Ubuntu 24.04 (Noble)
## Latency from Lab1 <> VPS1 (wireguard)
--- 10.8.0.1 ping statistics ---
10 packets transmitted, 10 received, 0% packet loss, time 9010ms
rtt min/avg/max/mdev = 1.769/2.709/7.532/1.660 ms
## Latency from Lab2 <> VPS1 (wireguard)
--- 10.8.0.1 ping statistics ---
10 packets transmitted, 10 received, 0% packet loss, time 9008ms
rtt min/avg/max/mdev = 6.354/6.671/7.018/0.172 ms
## Latency from Lab1 <> Lab2 (tailscale)
--- lab2 ping statistics ---
10 packets transmitted, 10 received, 0% packet loss, time 9009ms
rtt min/avg/max/mdev = 9.080/9.748/11.478/0.718 msArchitecture At a Glance
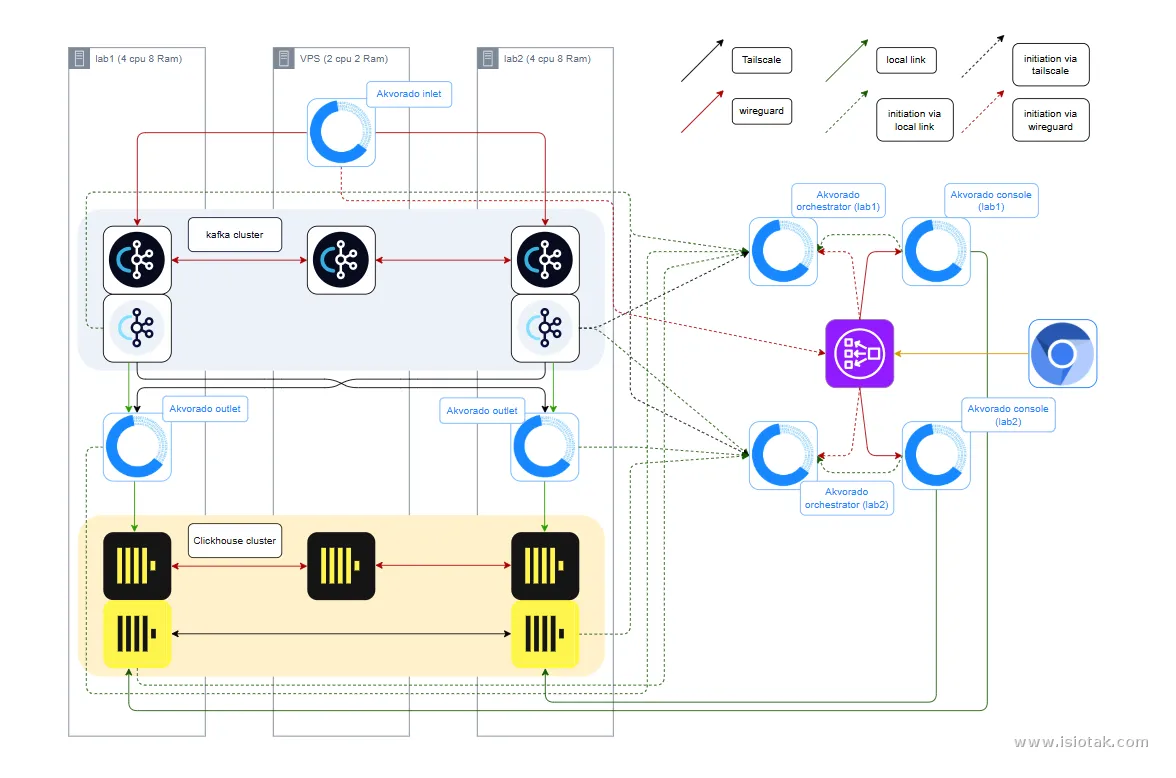
Akvorado docker image (quay.io/akvorado/akvorado:2.4.0)
Apache kafka docker image (apache/kafka:4.2.1)
Kafka UI docker image (kafbat/kafka-ui:v1.5.0)
clickhouse-keeper docker image (clickhouse/clickhouse-keeper:26.4-alpine)
clickhouse-server service (26.5.2.39)
Docker service (latest got version 29.5.0, build 98f1464)
Deskripsi tiap komponen
Karena kemungkinan teman-teman masih bingung tentang apasih akvorado(?) Disini saya akan jabarkan komponen apa saja dan fungsinya didalam akvorado. Untuk penjalasan lainnya akan menyusul setelah ini.
Akvorado Inlet
Gerbang yang menerima setiap flow exporter lalu akan dikiramkan ke antrian Kafka.Apache Kafka
Antrian yang berada di belakang gerbang (gateway), antrian ini membuat flow lebih ter-arah saat keluar nanti. Komponen ini juga yang akan menjadi loadbalancer.Akvorado Outlet
Tujuan keluar dari flow setelah mengantri, disini setiap flow yang berhasil masuk akan diberi identitas sebelum masuk ke database.Clickhouse
Database yang akan menyimpan flow yang sudah menerima identitas.Akvorado Console
Flow yang tersimpan dalam database akan dibaca dan divisualisasikan disini.Akvorado Orchestrator
Semua komponen di atas dikonfigurasi oleh komponen ini, komponen ini bertugas untuk memberikan instruksi awal dan data untuk identitas flow.
Komponen lainnya
Redis
komponen yang berguna sebagai penyimpanan sementara komponen Akvorado Console supaya bila mengakses panel yang sama terasa lebih cepat.Traefik
Traefik dibutuhkan karena semua komponen akvorado mengekspos port 8080 maka agar memudahkan diakses dari luar, traefik yang akan menjadi gerbang dengan melakukan reverse proxy.
2. Setup
Untuk bagian setup kali ini saya akan pecah menjadi beberapa bagian dan sebagian besar menggunakan docker compose agar mempermudah dalam rebuild host.
Prerequisites
Docker
Untuk setup docker saya menggunakan bash script yang telah disediakan oleh docker itu sendiri.
# get shell script and run it
curl https://get.docker.com | bash
# Install docker compose package
apt install docker-compose -yHost domain
Tambahkan ip cluster yang akan dibuat kedalam /etc/hosts. Tujuannya agar tiap ip bisa dipanggil dengan domain
# Add it at end of line
10.8.0.1 vps1
100.93.213.53 lab1
100.86.1.12 lab2Test domain
Setelah ditambahkan, jangan lupa untuk test domain satu persatu untuk memastikan satu sama lain dapat terhubung
#Run resolver test, because for some container need resolver from host
for i in vps1 lab1 lab2; do nslookup $i ; ping $i -c 1; done
## Expected value
# Server: 127.0.0.53
# Address: 127.0.0.53#53
# Name: vps1
# Address: 10.8.0.1
# PING vps1 (10.8.0.1) 56(84) bytes of data.
# 64 bytes from vps1 (10.8.0.1): icmp_seq=1 ttl=64 time=1.86 ms
# --- vps1 ping statistics ---
# 1 packets transmitted, 1 received, 0% packet loss, time 0ms
# rtt min/avg/max/mdev = 1.863/1.863/1.863/0.000 ms
# Server: 127.0.0.53
# Address: 127.0.0.53#53
# Name: lab1
# Address: 100.93.213.53
# PING lab1 (100.93.213.53) 56(84) bytes of data.
# 64 bytes from lab1 (100.93.213.53): icmp_seq=1 ttl=64 time=0.050 ms
# --- lab1 ping statistics ---
# 1 packets transmitted, 1 received, 0% packet loss, time 0ms
# rtt min/avg/max/mdev = 0.050/0.050/0.050/0.000 ms
# Server: 127.0.0.53
# Address: 127.0.0.53#53
# Name: lab2
# Address: 100.86.1.12
# PING lab2 (100.86.1.12) 56(84) bytes of data.
# 64 bytes from lab2 (100.86.1.12): icmp_seq=1 ttl=64 time=11.5 ms
# --- lab2 ping statistics ---
# 1 packets transmitted, 1 received, 0% packet loss, time 0ms
# rtt min/avg/max/mdev = 11.524/11.524/11.524/0.000 ms
##If failed on docker compose can use "extra_hosts" optionHaproxy
Buat rule loadbalance dengan menggunakan haproxy, untuk pembuatannya bisa edit konfigurasi file di haproxy.cfg
# Add it at end of line
frontend akvorado
bind *:4670
mode http
default_backend akvorado_backend
backend akvorado_backend
mode http
balance roundrobin
option httpchk GET /
http-check expect status 200
server vm 10.8.0.19:80 check
server laptop 10.8.0.8:80 checkKenapa ga pakai domain yang udah dibuat? Saya buat biar pakai existing domain aja.
Clickhouse cluster
Pengenalan singkat, Clickhouse adalah suatu Database Management System (DBMS) opensource yang digunakan untuk kebutuhan analisis atau disebut juga untuk Online Analythical Processing (OLAP).
Architecture
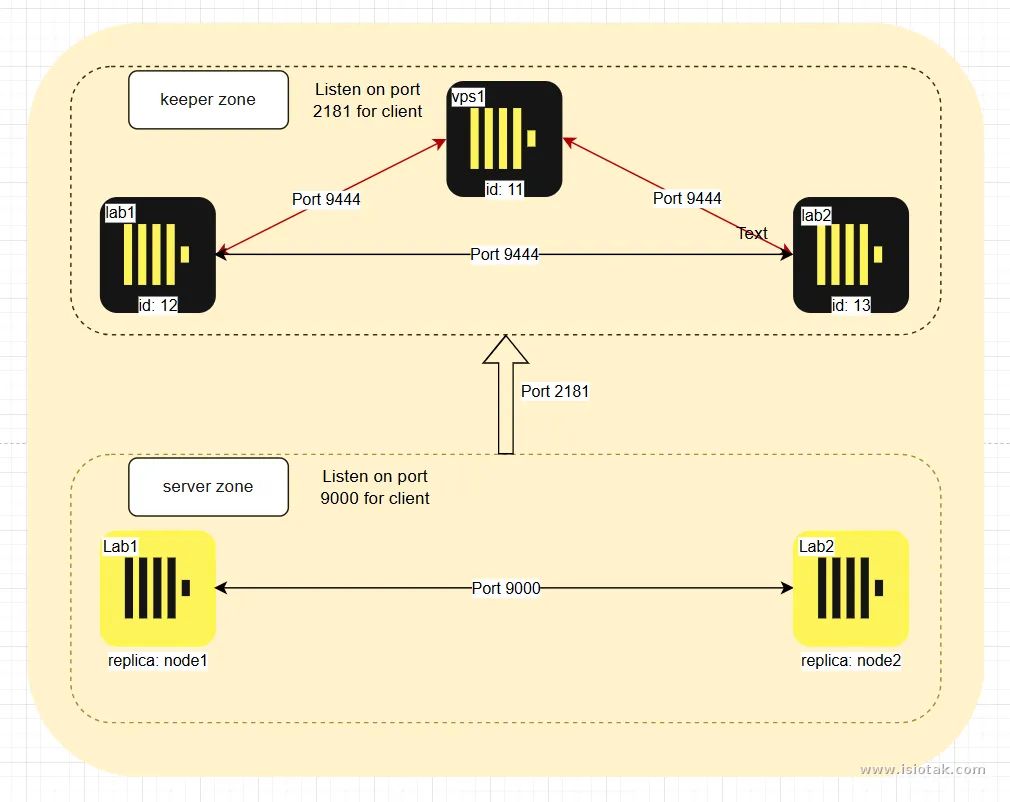
Untuk komponen ini saya deploy dengan menggabungkan container dan native systemd, dengan rincian sebagai berikut:
Clickhouse keeper
Deploy di seluruh host (vps1, lab1, lab2) menggunakan container, karena service ini ringan dan hanya bertugas sebagai controller. Service ini memerlukan minimal 3 node aktif untuk mencapai quorum (>50% host aktif) supaya tidak terjadi split-brain (kondisi saat host di dalam cluster jalan sendiri-sendiri tanpa koordinasi) atau tidak seragam. Untuk network mode, gunakan mode host agar lebih mudah terkoneksi dengan ClickHouse Server yang berjalan via systemd.Clickhouse Server
Deploy di Lab1 dan Lab2 langsung di atas native systemd, karena service ini yang mengelola dan menyimpan data sehingga butuh resource cukup besar. Konfigurasi yang digunakan adalah dua replika, di mana salah satunya sebagai shared. Untuk jalur replikasi, saya pakai Tailscale supaya tidak mengganggu trafik lainnya.
Clikchouse keeper Deploy as Container (vps1, lab1, lab2)
# create directory and go to created directory
mkdir clickhouse ; cd clickhouse
# create directory for container volume
mkdir -p keeper/{config,data}
# change ownership of directory
chown -R 101:101 keeper
# create config file
nano keeper/config/keeper_config.xml Perubahan ownership wajib dilakukan, karena container akan menggunakan user keeper.
Config file
<clickhouse>
<listen_host>0.0.0.0</listen_host>
<logger>
<console>1</console>
<console_log_level>information</console_log_level>
</logger>
<keeper_server>
<tcp_port>2181</tcp_port>
<!-- Make sure server id is same location as ratf_configuration say -->
<server_id>{ID}</server_id>
<snapshot_storage_path>/var/lib/clickhouse/coordination/snapshots</snapshot_storage_path>
<coordination_settings>
<operation_timeout_ms>10000</operation_timeout_ms>
<session_timeout_ms>30000</session_timeout_ms>
<raft_logs_level>trace</raft_logs_level>
</coordination_settings>
<raft_configuration>
<server>
<id>11</id>
<hostname>vps1</hostname>
<port>9444</port>
</server>
<server>
<id>12</id>
<hostname>lab1</hostname>
<port>9444</port>
</server>
<server>
<id>13</id>
<hostname>lab2</hostname>
<port>9444</port>
</server>
</raft_configuration>
</keeper_server>
</clickhouse>Pastikan block <server_id> memiliki id yang sesuai seperti mapping pada block <raft_configuration>
Compose file
#create compose file after create config file
nano docker-compose.yamlservices:
clickhouse-keeper:
image: clickhouse/clickhouse-keeper:26.4-alpine
container_name: clickhouse-keeper
restart: always
user: "101:101"
network_mode: host
volumes:
- ./clickhouse-keeper/config/keeper_config.xml:/etc/clickhouse-keeper/keeper_config.xml
- ./clickhouse-keeper/data:/var/lib/clickhouse
command: >
clickhouse-keeper --config-file=/etc/clickhouse-keeper/keeper_config.xmlUser 101 dipakai untuk menghindari error
Application: Code: 430. DB::Exception: Effective user of the process (root) does not match the owner of the data (clickhouse)akibat permission.
Test keeper connection
Sebelum melakukan testing connection, pastikan semua keeper harus sudah up pada tiap host. Apabila sudah berhasil UP, bisa lanjut untuk jalankan perintah dibawah ini
#Run it on any host
for h in vps1 lab1 lab2; do
echo -n "${h}: "
echo "stat" | nc ${h} 2181 2>/dev/null | grep Mode || echo "not ready"
done
#Expected value
vps1: Mode: follower
lab1: Mode: follower
lab2: Mode: leader
#Leader can be different, value must not containt "not ready"Clickhouse Server Deploy dengan Systemd (lab1, lab2)
Installation
Setup dapat dari situs resmi clickhouse (https://clickhouse.com/docs/install/debian_ubuntu#setup-the-debian-repository)
# Install prerequisite packages
sudo apt-get install -y apt-transport-https ca-certificates curl gnupg
# Download the ClickHouse GPG key and store it in the keyring
curl -fsSL 'https://packages.clickhouse.com/rpm/lts/repodata/repomd.xml.key' | sudo gpg --dearmor -o /usr/share/keyrings/clickhouse-keyring.gpg
# Get the system architecture
ARCH=$(dpkg --print-architecture)
# Add the ClickHouse repository to apt sources
echo "deb [signed-by=/usr/share/keyrings/clickhouse-keyring.gpg arch=${ARCH}] https://packages.clickhouse.com/deb stable main" | sudo tee /etc/apt/sources.list.d/clickhouse.list
# Update apt package lists
sudo apt-get update
# Install spesific version
apt install clickhouse-server=26.5.2.39 clickhouse-common-static=26.5.2.39
# Between installation process, there was intruction for default user password
#Creating pid directory /var/run/clickhouse-server.
# chown -R 'clickhouse':'clickhouse' '/var/log/clickhouse-server/'
# chown -R 'clickhouse':'clickhouse' '/var/run/clickhouse-server'
# chown 'clickhouse':'clickhouse' '/var/lib/clickhouse/'
#Set up the password for the default user:
# Make sure clickhouse is healthy
systemctl status clickhouse-server
# Create new configuration
nano /etc/clickhouse-server/config.d/cluster.xmlConfig file
<clickhouse>
<listen_host>0.0.0.0</listen_host>
<zookeeper>
<node><host>vps1</host><port>2181</port></node>
<node><host>lab1</host><port>2181</port></node>
<node><host>lab2</host><port>2181</port></node>
<session_timeout_ms>30000</session_timeout_ms>
<operation_timeout_ms>10000</operation_timeout_ms>
</zookeeper>
<remote_servers>
<!-- determine name for cluster -->
<lab_cluster>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>lab1</host>
<port>9000</port>
</replica>
<replica>
<host>lab2</host>
<port>9000</port>
</replica>
</shard>
</lab_cluster>
</remote_servers>
<macros>
<!-- For Shard because we just use one shard just leave it as is-->
<shard>1</shard>
<!-- For Replication Make sure replica block is different on each host-->
<replica>{ID}</replica>
</macros>
</clickhouse>Buat block <macros> ini buat subtitusi sebagai variable saat pembuatan table nanti, bisa apa saja sebagai identitas. Ini bisa keliatan metadanya lewat keeper client. Pastikan untuk replica ini berbeda di tiap host karena kita pakai 2 replica. Untuk memudahkan, setiap host memakai nama replica yang sama nomor-nya dengan host contoh, Lab1 replica <1>, Lab2 replica <2> dan nomor replica ini harus berurut berdasarkan urutan yang ada di block <remote_host>. Kenapa digambar architecture saya pakai <node1> bukan <1> ? karena existing dan sudah ada datanya jadi terlanjur.
Restart service
systemctl restart clickhouse-server.servicePASTIKAN SEMUA SERVER SUDAH TERDEPLOY DISEMUA HOST DAN SEMUANYA UP
Test server connection
#go to any clickhouse-server host and access database
clickhouse-client
#check cluster system, make sure all configured host is exist
SELECT * FROM system.clusters
#create database
CREATE DATABASE netflow ON CLUSTER lab_cluster
#expected value
Query id: fdf1ab39-9cad-4f6c-82b5-c810c5ebb22e
┌─host─┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
1. │ lab1 │ 9000 │ 0 │ │ 1 │ 1 │
2. │ lab2 │ 9000 │ 0 │ │ 0 │ 0 │
└──────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
2 rows in set. Elapsed: 0.357 sec.Kafka Cluster
Pengenalan singkat, kafka adalah sebuah platform open source yang menerima, meyimpan, mendistribusikan event/data (event streaming) secara berkelanjutan, untuk data yang disimpan bisa diatur dalam jangka waktu tertentu, sehingga consumer (penerima) bisa mengambil dan mengelola data yang terlewat bila terjadi loss connection atau tidak aktif.
Architecture
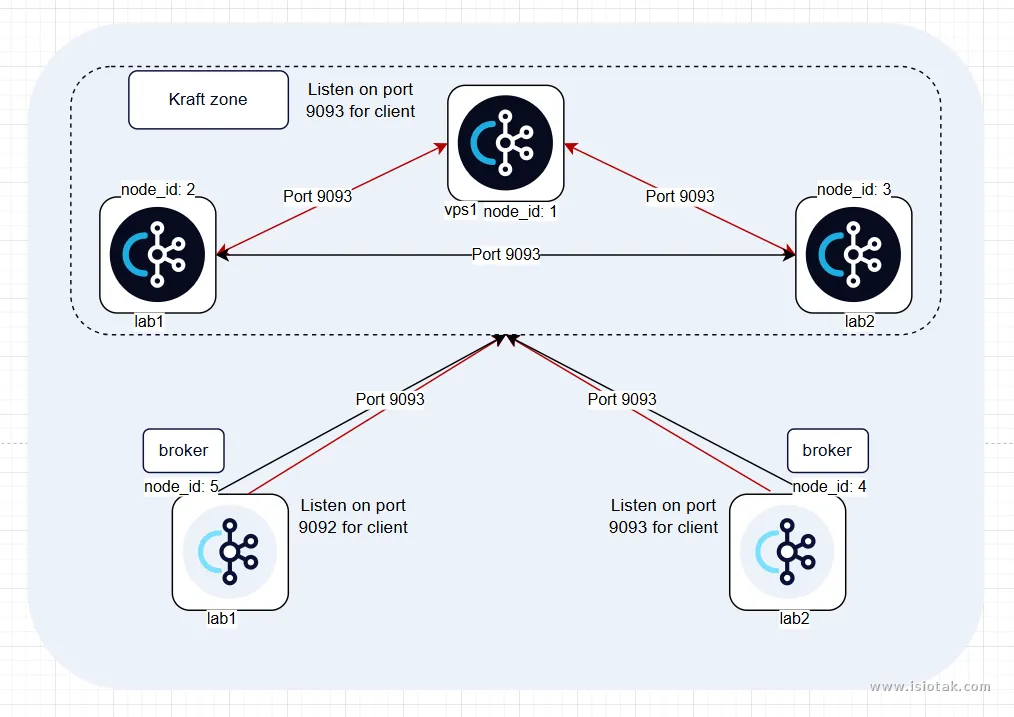
BTW. Apakah kalian sadar ada perbedaan pada sistem clustering dengan clickhouse? kafka broker tidak perlu konfigurasi tambahan supaya bisa melakukan replikasi. Tidak seperti clickhouse yang dimana replikasi disetting di sisi clickhouse server, untuk kafka, broker akan menerima data dari leader partition layaknya consumer. Apa itu leader partition? Jadi setiap data yang diterima dalam kafka akan dibagi ke beberapa partisi yang ada didalam topic (tempat menyimpan data/event) . Nah dalam cluster, kafka akan mengatur leader dan follower lewat partisi ini, yang menentukan siapa? Controller. Jadi datanya dipecah dulu, bukan dalam kesatuan
Untuk komponen ini saya deploy menggunakan full container, dengan rincian
Kraft (Kafka Raft)
Deploy di seluruh host (vps1, lab1, lab2) karena service ini ringan dan hanya bertugas sebagai controller. Juga, service ini minimal memerlukan tiga yang aktif untuk mencapai quorum (pemungutan suara lebih dari 50% host aktif) supaya tidak split brain (host yang berbeda dalam cluster bekerja sendiri tanpa koordinasi). Nyalin dari yang atas btw, masih sama soalnya.Kafka Broker
Deploy di lab1 dan lab2 karena service ini yang bakal mengelola data masuk dan keluar, cukup berat. Terus kenapa gk pake native systemd? Walaupun berat, tapi tidak seberat clickhouse yang mana dia mengelola dan menyimpan data. Retention data yang disetting juga cuman satu hari dan untuk workload lab saya sekarang juga belum seberat itu. Juga, alasan lainnya adalah kemudahan dalam mengatur control group (sesuatu yang dapat dimiliki container) misalnya resource. Semisal, ada kegagalan hingga consumer tidak dapat mengambil data dalam waktu lama, kita bisa control resource dengan mudah agar tidak bengkak.
Deploy using docker compose
vps1
#Create directory and change directory
mkdir kafka ; cd kafka
#Create directory for data
mkdir data-controller
#Change ownership based on container user
docker run --rm apache/kafka:4.2.1 id
#uid=1000(appuser) gid=1000(appuser) groups=1000(appuser)
chown -R 1000:1000 data-controller
#generate cluster id for identification
docker run --rm apache/kafka:4.2.1 /opt/kafka/bin/kafka-storage.sh random-uuid
#save it for later
#Create docker-compose.yaml file
nano docker-compose.yamlSebenernya semisal pakai docker volume tidak perlu mengatur permission lagi, cuman saya tidak pakai karena saya punya scipt backup yang mengarah ke parent directory seluruh file compose. Jadi, supaya tidak bikin target baru buat backup mending atur ownership saja. Lalu, kenapa pakai user 1000 (reguler user)? ini sama seperti image clickhouse di atas kasus-nya. tambahan, beda sedikit dengan image clickhouse yang dimana dia lebih sensitif ketika data owner-nya beda dengan user id container akan muncul error sedangkan Kafka selama owner-nya sesuai dengan process yang berjalan dalam container (bisa dilihat dengan
docker compose top) tidak akan muncul error walaupun user id container default (root).
Compose file
services:
kafka-controller:
image: apache/kafka:4.2.1
restart: unless-stopped
environment:
CLUSTER_ID: <generated_cluster_id>
# For id, just adjust it like in architecture image
KAFKA_NODE_ID: <id>
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: CLIENT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CLIENT:PLAINTEXT,CONTROLLER:PLAINTEXT
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@vps1:9093,2@lab1:9093,3@lab2:9093
KAFKA_LOG_DIRS: /var/lib/kafka/data
volumes:
- ./data-controller:/var/lib/kafka/data
ports:
- 9093:9093
extra_hosts:
vps1: 10.8.0.1
lab1: 100.93.213.53
lab2: 100.86.1.12Disini saya menggunakan option "extra_hosts" karena saat menjalankan test domain dengan command
for i in vps1 lab1 lab2; do nslookup $i ; ping $i -c 1; donepada bagian nslookup ini gagal. Yang dapat menyebabkan container bingung tidak bisa lookup domain yang sudah di setup sebelumnya. Ini biasanya berlaku bagi yang menggunakan host sebagai resolver (biasanya docker network) tetapi host memakai resolver luar bukan loopback (127.0.0.53).contoh saat menjalankan
nslookupnslookup vps1
Server: 1.1.1.1
Address: 1.1.1.1#53
** server can't find vps1: NXDOMAIN
Run it
docker compose up
lab1 and lab2
#Create directory and change directory
mkdir kafka ; cd kafka
#Create directory for data
mkdir data-{broker,controller}
#Change ownership based on container user
docker run --rm apache/kafka:4.2.1 id
#uid=1000(appuser) gid=1000(appuser) groups=1000(appuser)
chown -R 1000:1000 data-{broker,controller}
#Create docker-compose.yaml file
nano docker-compose.yamlCompose file
services:
kafka-controller:
image: apache/kafka:4.2.1
restart: unless-stopped
environment:
CLUSTER_ID: <generated_cluster_id>
# For id, just adjust it like in architecture image
KAFKA_NODE_ID: <id>
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: CLIENT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CLIENT:PLAINTEXT,CONTROLLER:PLAINTEXT
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@vps1:9093,2@lab1:9093,3@lab2:9093
KAFKA_LOG_DIRS: /var/lib/kafka/data
volumes:
- ./data-controller:/var/lib/kafka/data
ports:
- 9093:9093
kafka-broker:
image: apache/kafka:4.2.1
ports:
- 9092:9092
restart: unless-stopped
environment:
CLUSTER_ID: <generated_cluster_id>
# For id, just adjust it like in architecture image
KAFKA_NODE_ID: <id>
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: CLIENT://:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CLIENT:PLAINTEXT,CONTROLLER:PLAINTEXT
# Make sure KAFKA_ADVERTISED_LISTENERS is configured as curent host domain
KAFKA_ADVERTISED_LISTENERS: CLIENT://<domain>:9092
KAFKA_INTER_BROKER_LISTENER_NAME: CLIENT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@vps1:9093,2@lab1:9093,3@lab2:9093
KAFKA_DELETE_TOPIC_ENABLE: "true"
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 2
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 2
KAFKA_SHARE_COORDINATOR_STATE_TOPIC_REPLICATION_FACTOR: 2
KAFKA_SHARE_COORDINATOR_STATE_TOPIC_MIN_ISR: 1
KAFKA_MIN_INSYNC_REPLICAS: 1
KAFKA_LOG_DIRS: /var/lib/kafka/data
depends_on:
- kafka-controller
volumes:
- ./data-broker:/var/lib/kafka/data
healthcheck:
interval: 20s
test: ["CMD",
"/opt/kafka/bin/kafka-topics.sh", "--list", "--bootstrap-server", "localhost:9092"]
kafka-ui:
image: kafbat/kafka-ui:v1.5.0
restart: unless-stopped
depends_on:
kafka-broker:
condition: service_healthy
environment:
KAFKA_CLUSTERS_0_NAME: wahaha
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: lab1:9092,lab2:9092
ports:
- 8180:8080Sekedar pengingat, Untuk yang diubah dari file compose hanya KAFKA_NODE_ID sebagai identifier. Karena implementasi ini di homelab saya maka bisa mengikuti pemetaan yang ada di gambar architecture. Lalu, untuk CLUSTER_ID harus sama semua untuk setiap node/host yang join cluster. Jangan lupa juga ubah KAFKA_ADVERTISED_LISTENERS berdasarkan domain dari host yang sedang dikonfigurasi atau lihat permetaan juga bisa. Soalnya nilai ini yang akan menjadi metadata untuk broker. Contohnya saat client ingin terhubung ke broker walau client bisa mengakses broker, tapi saat ingin mengirim data nilai KAFKA_ADVERTISED_LISTENERS yang akan menjadi patokan kirim kemana.
Run it
docker compose up
PASTIKAN SEMUA KAFKA CONTAINER SUDAH TERDEPLOY DISEMUA HOST DAN SEMUANYA UP
Test cluster connection
#Run it on any host at compose location (for check joined node)
docker compose exec kafka-controller /opt/kafka/bin/kafka-metadata-quorum.sh --bootstrap-controller localhost:9093 describe --status
## expected value
#ClusterId: 4L62YDgNTki98R7vDuBgUA
#LeaderId: 2
#LeaderEpoch: 129
#HighWatermark: 1984791
#MaxFollowerLag: 0
#MaxFollowerLagTimeMs: 374
#CurrentVoters: [{"id": 1, "endpoints": ["CONTROLLER://vps1:9093"]}, {"id": 2, "endpoints": ["CONTROLLER://lab1:9093"]}, {"id": 3, "endpoints": ["CONTROLLER://lab2:9093"]}]
#CurrentObservers: [{"id": 4, "directoryId": "1qBQVeplgBNfDTFMwvrWkw"}, {"id": 5, "directoryId": "GVLOqKY1RjqcFXmSX4xJlA"}]
#Run it on any host at compose location (for check node position)
docker compose exec kafka-controller /opt/kafka/bin/kafka-metadata-quorum.sh --bootstrap-controller localhost:9093 describe --status
## expected value (leader can be different) make sure all lag value is near zero
#NodeId DirectoryId LogEndOffset Lag LastFetchTimestamp LastCaughtUpTimestamp Status
#2 AAAAAAAAAAAAAAAAAAAAAA 1985300 0 1782542539711 1782542539711 Leader
#1 AAAAAAAAAAAAAAAAAAAAAA 1985300 0 1782542539272 1782542539272 Follower
#3 AAAAAAAAAAAAAAAAAAAAAA 1985300 0 1782542539288 1782542539288 Follower
#4 1qBQVeplgBNfDTFMwvrWkw 1985300 0 1782542539283 1782542539283 Observer
#5 GVLOqKY1RjqcFXmSX4xJlA 1985300 0 1782542539271 1782542539271 ObserverAkvorado
Karena diawal kita sudah kenalan sama akvorado dan beberapa komponennya jadi saya lanjut ke architecture-nya aja
Architecture
Untuk gambarannya masih sama kayak awalan dan untuk deploy nya full sebagai container, dengan rincian
Inlet
Deploy cuman di vps1 karena tugasnya yang mengumpulkan data dan vps1 adalah host penghubung dari semuanya atau bisa dibilang juga router dari homelab saya. Sama, komponen ini berat di load jaringan dan ringan di load cpu, memory jadi cocok simpan di vps1.Outlet
Deploy di lab1 dan lab2, jadi outlet akan langsung terhubung ke clickhouse secara lokal dan identifier akan dibedakan untuk melihat apakah kafka melakukan load balance dengan baik.Orchestrator
Deploy di lab1 dan lab2 juga, Karena secara konfigurasi bakal ada yang berbeda dan untuk mengurasi latensi saat melakukan inisiasi.Console
Deploy di lab1 dan lab2 juga, supaya dapat menampilkan data secara cepat dan untuk membagi trafik saat mengakses data.
Buat komponen Redis dan Traefik deploynya di kedua sisi soalnya mereka komponen pendukung yang akan selalu ada dalam satu file compose untuk membantu keberlangsungan komponen lain. Penjelasan fungsi sama seperti diawal.
Deploy using docker compose
vps1
#Create directory and change directory
mkdir akvorado ; cd akvorado
#Create docker compose file
nano docker-compose.yamlCompose file
services:
akvorado-inlet:
image: quay.io/akvorado/akvorado:2.4.0
network_mode: "host"
restart: unless-stopped
command: inlet http://vps1:4670Di up nya nanti saja saat semua komponen sudah berjalan
lab1 dan lab2
Buat full nya bisa lihat ke repositori saya https://github.com/fareisa/akvorado-deploy-comparison.git cuman belum diberi teks dokumentasi, nunggu postingan ini dulu ke publish.
#Create directory
mkdir akvorado
#Get akvorado quickstart dokcer compose file
wget https://github.com/akvorado/akvorado/releases/download/v2.4.0/docker-compose-quickstart.tar.gz
#Extract to created directory
tar -xzvf docker-compose-quickstart.tar.gz -C akvorado
#Change directory
cd akvorado
#edit docker compose file
nano docker/docker-compose.ymlEditing docker-compose.yml
Untuk bagian ini hanya beberapa saja yang di-edit untuk mengurangi kompleksitas, sisanya biarin default saja.
Network and volume
networks:
default:
enable_ipv6: true
ipam:
config:
- subnet: 247.16.14.0/24
gateway: 247.16.14.1 #Set static gateway because for connection to the clickhouse
# - subnet: fd1c:8ce3:6fb:1::/64
driver: bridge
driver_opts:
com.docker.network.bridge.name: br-akvorado
volumes:
# akvorado-kafka:
akvorado-geoip:
# akvorado-clickhouse:
akvorado-run:
akvorado-console-db:Pageri atau jadikan komentar option yang tidak terpakai, karena sudah terdeploy sebelumnya
Disable kafka service

Pageri juga dua service ini karena sudah ter-deploy
Orchestrator
akvorado-orchestrator:
extends:
file: versions.yml
service: akvorado
restart: unless-stopped
depends_on:
kafka:
condition: service_healthy
command: orchestrator /etc/akvorado/akvorado-default.yaml
volumes:
- ../config:/etc/akvorado:ro
- akvorado-geoip:/usr/share/GeoIP:ro
labels:
- traefik.enable=true
# Disable access logging of /api/v0/orchestrator/metrics
- traefik.http.routers.akvorado-orchestrator-metrics.rule=PathPrefix(`/api/v0/orchestrator/metrics`)
- traefik.http.routers.akvorado-orchestrator-metrics.service=akvorado-orchestrator
- traefik.http.routers.akvorado-orchestrator-metrics.observability.accesslogs=false
# Everything else is exposed to private entrypoint in /api/v0/orchestrator
- traefik.http.routers.akvorado-orchestrator.entrypoints=public #change to public
- traefik.http.routers.akvorado-orchestrator.rule=PathPrefix(`/api/v0/orchestrator`)
- traefik.http.services.akvorado-orchestrator.loadbalancer.server.port=8080
- metrics.enable=true
- metrics.path=/api/v0/metricsConsole
akvorado-console:
extends:
file: versions.yml
service: akvorado
restart: unless-stopped
depends_on:
akvorado-orchestrator:
condition: service_healthy
redis:
condition: service_healthy
# clickhouse:
# condition: service_healthy
command: console http://akvorado-orchestrator:8080
volumes:
- akvorado-console-db:/run/akvorado
environment:
AKVORADO_CFG_CONSOLE_DATABASE_DSN: /run/akvorado/console.sqlite
AKVORADO_CFG_CONSOLE_BRANDING: ${AKVORADO_CFG_CONSOLE_BRANDING-false}
healthcheck:
disable: ${CONSOLE_HEALTHCHECK_DISABLED-false}
labels:
- traefik.enable=true
# Only expose /debug endpoint on the private entrypoint.
- traefik.http.routers.akvorado-console-debug.rule=PathPrefix(`/debug`)
- traefik.http.routers.akvorado-console-debug.entrypoints=private
- traefik.http.routers.akvorado-console-debug.service=akvorado-console
# Disable access logging of /api/v0/console/metrics
- traefik.http.routers.akvorado-console-metrics.rule=PathPrefix(`/api/v0/console/metrics`)
- traefik.http.routers.akvorado-console-metrics.service=akvorado-console
- traefik.http.routers.akvorado-console-metrics.observability.accesslogs=false
# For anything else...
- "traefik.http.routers.akvorado-console.rule=!PathPrefix(`/debug`)"
- traefik.http.routers.akvorado-console.priority=1
- traefik.http.routers.akvorado-console.middlewares=console-auth
- traefik.http.services.akvorado-console.loadbalancer.server.port=8080
- traefik.http.middlewares.console-auth.headers.customrequestheaders.Remote-User=alfred
- traefik.http.middlewares.console-auth.headers.customrequestheaders.Remote-Name=Alfred Pennyworth
- traefik.http.middlewares.console-auth.headers.customrequestheaders.Remote-Email=alfred@example.com
- metrics.enable=true
- metrics.path=/api/v0/metricscuman disable pengecekan ke clickhouse
Disable inlet

Disable service inlet karena sudah ada
Outlet
akvorado-outlet:
extends:
file: versions.yml
service: akvorado
# ports:
# - 10179:10179/tcp
restart: unless-stopped
stop_grace_period: 30s
depends_on:
akvorado-orchestrator:
condition: service_healthy
# kafka:
# condition: service_healthy
# clickhouse:
# condition: service_healthy
command: outlet http://akvorado-orchestrator:8080
volumes:
- akvorado-run:/run/akvorado
environment:
AKVORADO_CFG_OUTLET_METADATA_CACHEPERSISTFILE: /run/akvorado/metadata.cache
AKVORADO_CFG_OUTLET_FLOW_STATEPERSISTFILE: /run/akvorado/flow.state
labels:
- traefik.enable=true
# Disable access logging of /api/v0/outlet/metrics
- traefik.http.routers.akvorado-outlet-metrics.rule=PathPrefix(`/api/v0/outlet/metrics`)
- traefik.http.routers.akvorado-outlet-metrics.service=akvorado-outlet
- traefik.http.routers.akvorado-outlet-metrics.observability.accesslogs=false
# Everything else is exposed to private entrypoint in /api/v0/outlet
- traefik.http.routers.akvorado-outlet.entrypoints=public #change to public
- traefik.http.routers.akvorado-outlet.rule=PathPrefix(`/api/v0/outlet`)
- traefik.http.services.akvorado-outlet.loadbalancer.server.port=8080
- metrics.enable=true
- metrics.port=8080
- metrics.path=/api/v0/metricsdisable port 10179 (protocol bmp) karena lab saya tidak pakai
Disable Clickhouse

Disable service
Traefik
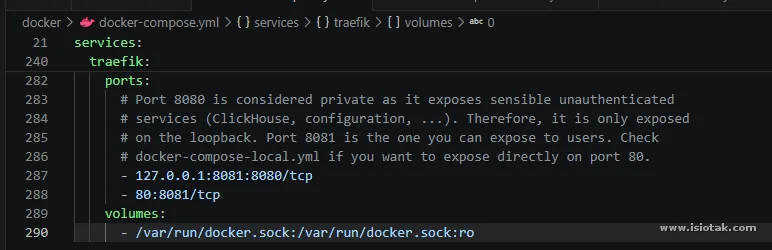
Disini cuman menyesuaikan port buat entrypoint private (8080) dan public (8081), sesuaikan dengan ketersedian port saja
PASTIKAN EDIT DI KEDUA LAB
Editing config file
Buat lokasi config filenya ada di folder config masih se-level dengan folder docker
editing akvorado.yaml
---
kafka:
topic: flows
#Add configured broker
brokers:
- lab1:9092
- lab2:9092
topic-configuration:
num-partitions: 8
replication-factor: 2 #change replication value
config-entries:
# The retention policy in Kafka is mainly here to keep a buffer
# for ClickHouse.
segment.bytes: 1073741824
retention.ms: 86400000 # 1 day
cleanup.policy: delete
compression.type: producerDisini cuman nambah broker dan ganti nilai replikasi buat topic yang akan dibuat nanti, sisanya bawaan
clickhousedb:
servers: 247.16.14.1:9000 #gateway docker network
username: "default"
password: "<configured_password>" #previous configured default user
cluster: "lab_cluster" #if block cluster name didnt change
database: "netflow" #previous create database for testdisini menyesuaikan seperti yang sudah disetting sebelumnya
clickhouse:
orchestrator-url: http://247.16.14.1 #connect to orchestrator via configured public entrypoint
asns:
64512: rumah network
64513: kos network
64514: wireguard network
64515: tailscale network
networks:
192.168.1.0/24:
name: ipv4-nethome
role: isp
site: kos
asn: 64513
country: ID
state: Jakata Selatan
city: Ragunan
192.168.100.0/24:
name: ipv4-xl-home
role: isp
site: rumah
asn: 64512
country: ID
state: Jawa Barat
city: Kab Sukabumi
192.168.11.0/24:
name: ipv4-server-1
role: server
site: rumah
asn: 64512
country: ID
state: Jawa Barat
city: Kab Sukabumi
192.168.12.0/24:
name: ipv4-server-2
role: server
site: rumah
asn: 64512
country: ID
state: Jawa Barat
city: Kab Sukabumi
172.16.10.0/24:
name: ipv4-wifi-rumah
role: wifi
site: rumah
asn: 64512
country: ID
state: Jawa Barat
city: Kab Sukabumi
172.16.20.0/24:
name: ipv4-wifi-p2p
role: wifi
site: rumah
asn: 64512
country: ID
state: Jawa Barat
city: Kab Sukabumi
10.8.0.0/24:
name: ipv4-wireguard
role: tunnel
asn: 64514
country: ID
100.93.213.53/32:
name: ipv4-tailscale-lab1
role: tunnel
site: rumah
asn: 64515
country: ID
100.86.1.12/32:
name: ipv4-tailscale-lab2
role: tunnel
site: kos
asn: 64515
country: ID
resolutions: #How much data is stored
- interval: 0
ttl: 168h #7 days
- interval: 1m
ttl: 168h #7 days
- interval: 5m
ttl: 360h #15 days
- interval: 1h
ttl: 720h #30 days
# network-sources: []
network-sources:
amazon:
url: https://ip-ranges.amazonaws.com/ip-ranges.json
interval: 6h
transform: |
(.prefixes + .ipv6_prefixes)[] |
{ prefix: (.ip_prefix // .ipv6_prefix), tenant: "amazon", region: .region, role: .service|ascii_downcase }
gcp:
url: https://www.gstatic.com/ipranges/cloud.json
interval: 6h
transform: |
.prefixes[] |
{ prefix: (.ipv4Prefix // .ipv6Prefix), tenant: "google-cloud", region: .scope }
nerd-scan:
url: https://nerd.cesnet.cz/nerd/data/bl_scan.txt
parser: plain
interval: 24h
transform: |
.[] | select(startswith("#") | not) |
{ prefix: . + "/32", tenant: "nerd", role: "nerd-scan" }Pengaturan ini berguna untuk identitas tambahan supaya tidak memberatkan database yang menyimpan flow. Pengaturan ini menyesuaikan lingkungan homelab.
PASTIKAN EDIT DI KEDUA LAB
editing outlet.yaml
---
#optional setting default value was "akvorado"
kafka:
consumer-group: wahaha-group
metadata:
providers:
- type: snmp
credentials:
::/0:
communities:
- public Buat kafka consumer-group itu bebas mau ada atau tidak soalnya cuman buat nama group saja. Metadata ini berguna buat snmp polling disini saya make SNMPv2 dan pakai communites key public buat semua IP supaya gampang buat konfigurasi nanti.
core:
default-sampling-rate: 1 #this crucial value for most exporter who doesnt have sampling rate value on given flow
exporter-classifiers:
- ClassifySite('wahaha-lab1')
- ClassifyRegion("kos")
interface-classifiers:
- |
ClassifyConnectivityRegex(
Interface.Name,
"^(ether1|eth0|enp0s31f6|nic1|nic0)$",
"WAN"
) &&
ClassifyProviderRegex(Interface.Description, "^(.*)$", "$1") &&
ClassifyExternal()
- |
ClassifyConnectivityRegex(
Interface.Name,
"^(wg.*)$",
"wireguard"
) &&
ClassifyInternal()
- |
ClassifyConnectivityRegex(
Interface.Name,
"^(tailscale.*)$",
"tailscale"
) &&
ClassifyInternal()
- |
ClassifyConnectivity("LAN") &&
ClassifyInternal()Nah, untuk bagian pada exporter-classifiers karena saya mau sekalian mau tes loadbalance dari kafka, disini saya bedakan pada lab1 dan lab2. Di mana lab1 sebagai wahaha-lab1 region kos dan lab2 sebagai wahaha-lab2 region rumah. Lalu untuk interface-classifiers ini berguna untuk memudahkan kita saat di dashboard nanti, dimana kita perlu memisahkan ClassifyExternal() dan ClassifyInternal() supaya flow arah tidak campur aduk dengan lokal. Buat ClassifyExternal() bisa disesuaikan dengan nama interface WAN exporter masing masing
PASTIKAN EDIT DI KEDUA LAB
editing console.yaml
---
homepage-top-widgets: [src-as, src-country, src-port, dst-port, exporter]
homepage-graph-timerange: 1h
default-visualize-options:
graph-type: sankey
start: 1 hours ago
end: now
filter: InIfBoundary = external #monitor external / WAN interfaces
dimensions:
- ExporterSite
- ExporterName
http:
cache:
type: redis
server: redis:6379
database:
saved-filters:Buat disini saya tidak bikin filter apa - apa, sama disini juga saya ubah dimensi default biar tahu bahwa load balance berjalan lancar.
PASTIKAN EDIT DI KEDUA LAB
DOCKER COMPOSE UP!!
lab1 dan lab2
## run docker compose up
docker compose up
## detach if theres no problemvps1
## run docker compose up, container will restarting if theres no active orchestrator
docker compose up
## detach if theres no problemExporter
Untuk saat ini saya cuman pakai netflow exporter
Ubuntu noble (pmacct)
configure pmacct
Bawaan repo pakai pmacct versi 1.7.8-2build2
#update repository
apt update
#install pmacct package
apt install pmacct
#edit pmacctd config file
nano /etc/pmacct/pmacctd.confpmacct config file
daemonize: true
plugins: nfprobe[any]
nfprobe_source_ip: 10.8.0.8
nfprobe_receiver: 10.8.0.1:2055
aggregate: src_host,dst_host,in_iface,out_iface,src_port,dst_port,proto
pcap_ifindex: map
pcap_interfaces_map: /etc/pmacct/interfaces.map
pcap_interface_wait: true
nfprobe_version: 9
nfprobe_timeouts: tcp=15:tcp.rst=15:tcp.fin=15:udp=15:icmp=15:general=30:maxlife=60:expint=5time out sengaja dipercepat supaya jika ada flow yang lama (misal download), flow tersebut bisa di potong potong sesuai timeout sehingga data yang terlihat bisa mendekati realtime
kalau mau lebih realtime bisa aktifkan opsi
nfprobe_dont_cache: true
minusnya flow bakal bengkak
Create interface map
#check which interfaces who want to monitoring it
ip -c a
####
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether bc:24:11:ef:aa:db brd ff:ff:ff:ff:ff:ff
altname enp0s18
inet 192.168.12.251/24 metric 100 brd 192.168.12.255 scope global dynamic eth0
valid_lft 1039sec preferred_lft 1039sec
inet6 fe80::be24:11ff:feef:aadb/64 scope link
valid_lft forever preferred_lft forever
####
#create interfaces map
nano /etc/pmacct/interfaces.mapifindex=1 ifname=lo direction=in
ifindex=1 ifname=lo direction=out
ifindex=2 ifname=eth0 direction=in
ifindex=2 ifname=eth0 direction=outconfigure snmp
Bawaan repo pakai snmpd versi 5.9.4+dfsg-1.1ubuntu3.2
#Install package
apt install snmpd
#configure snmpd
nano /etc/snmp/snmpd.confconfig file
##change all concurrent option like below
agentaddress udp:161,udp6:161
rocommunity public
rocommunity6 publicrestart for applying config
#Restart pmacctd and snmpd
systemctl restart pmacctd.service
systemctl restart snmpd.serviceMikrotik Ros 7.22
Configure traffic flow
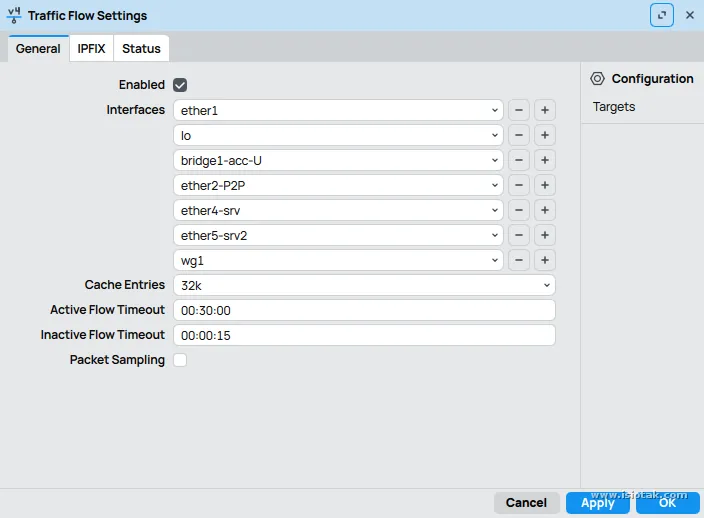
pilih interface mana yang mau dicapture, sisanya biarkan default
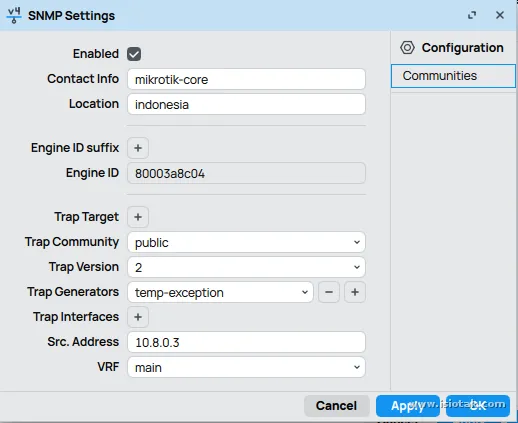
Configure snmp
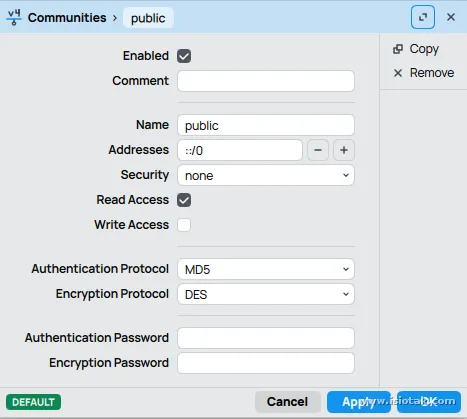
Check
Outlet
Untuk mempersingkat, pengecekan bisa berpatokan dari nilai metrics komponen outlet cek lab1 dan lab2
#Chekc if flow is got forward
watch -n1 "curl http://10.8.0.8/api/v0/outlet/metrics | grep forward"semisal ada IP exporter dan nilai-nya berubah berarti flow sudah berjalan dan dapat dimonitoring
Console
Untuk access bisa ke port 4670 ke vps1 (haproxy)
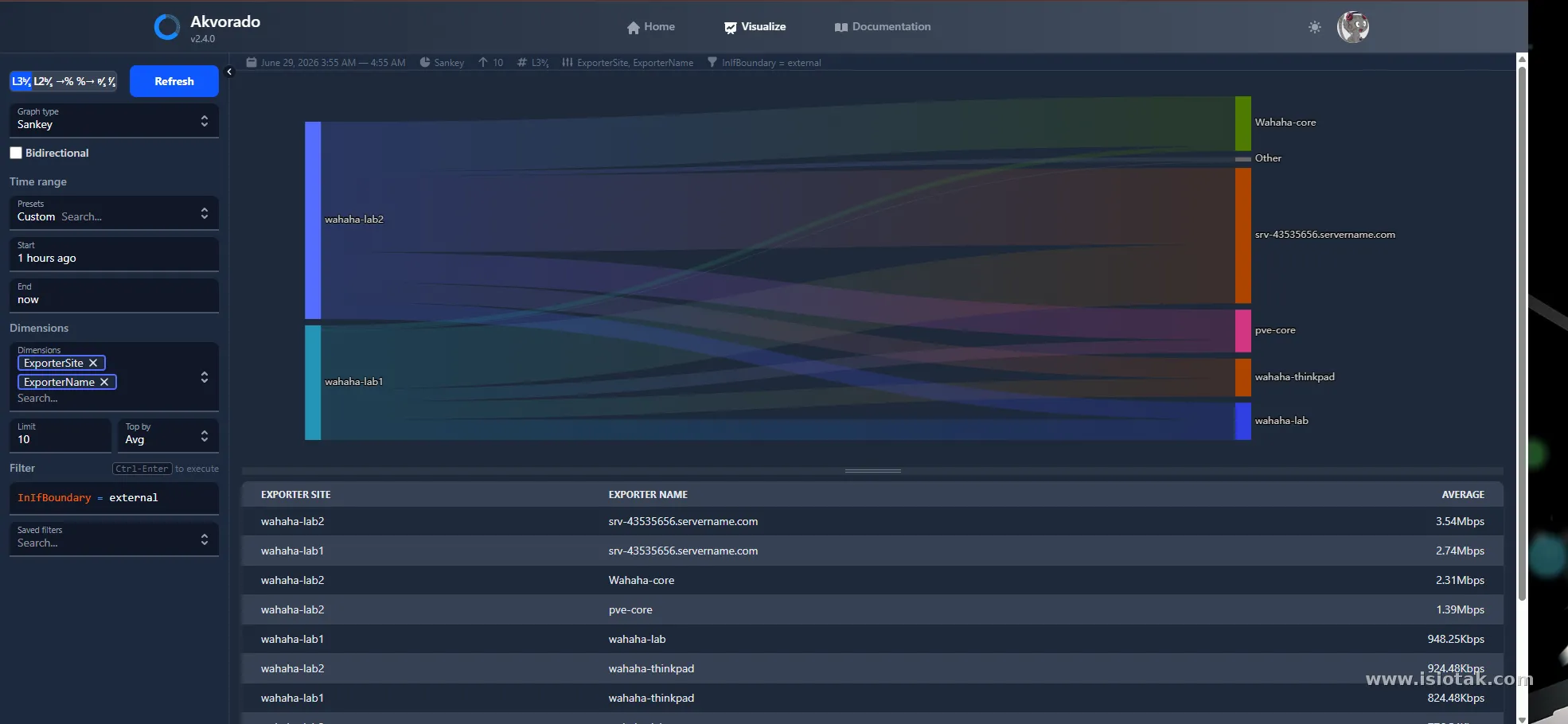
Bisa dilihat juga bagaimana kafka melakukan loadbalancing pada consumer yang tersedia
kafka
Untuk access bisa ke port 8180 ke lab1 dan lab2
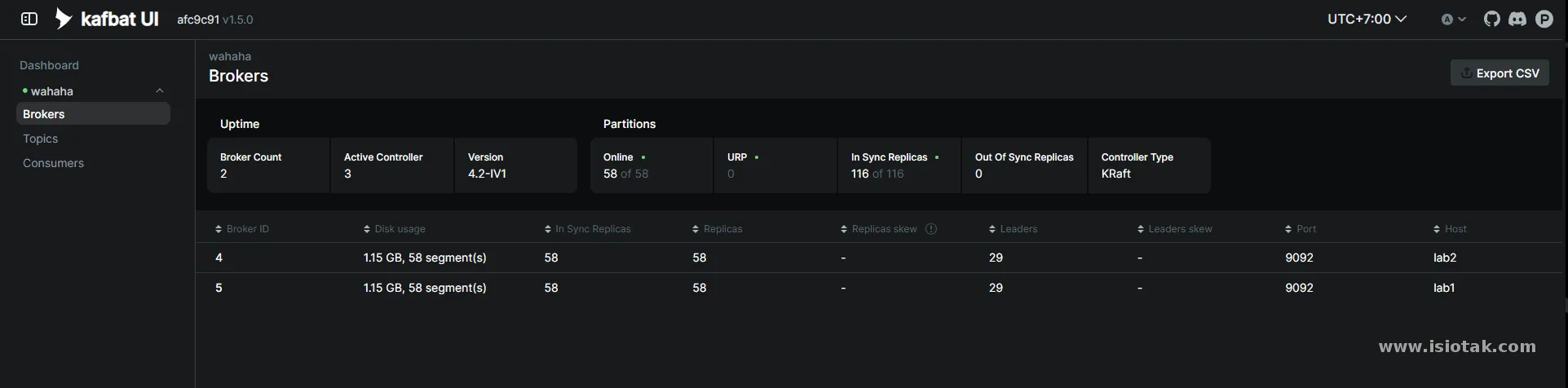
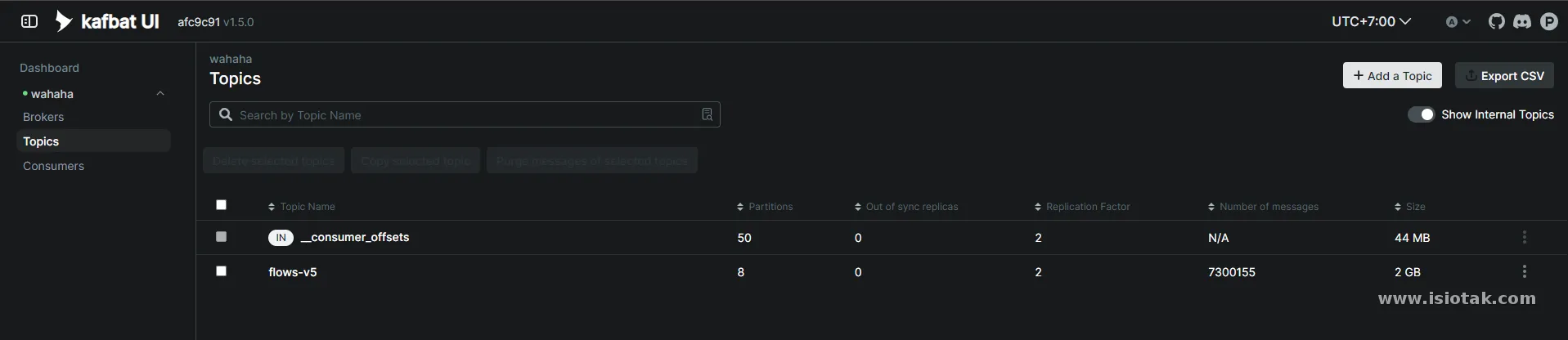
clickhouse
access clickhouse server ke lab1 dan lab2
#Make sure table get created
SHOW TABLES FROM netflow
#Make sure network identifier in clickhouse is loaded
SELECT *
FROM system.dictionaries
WHERE name = 'networks'Kesimpulan
Sebenarnya tool ini buat apa sih? kalau kegunaan buat saya sendiri sih tool ini lumayan berguna untuk melihat trafik jaringan. Soalnya, saya pernah sempat bingung, ini home lab kok bisa lambat di akses nya? karena resource hardware kah? atau jaringan? kalau jaringan siapa dan akses apa. nah dengan tool ini saya bisa mengurangi pertanyaan - pertanyaan tersebut. Mungkin memang terlihat overkill tapi lumayan menarik untuk dicoba.
Oh iya, awal mula saya tertarik dengan tool ini dibandingkan tool yang sejenis itu karena artikel ini (https://hostkey.com/blog/113-review-of-the-akvorado-netflow-collector-with-visualization-from-deployment-to-practical-use/). Mungkin bisa dijadikan buat referensi juga buat yang lainnya.
Oke sekian, Terima kasih sudah membaca sejauh ini.
Referensi
https://towardsdev.com/a-guide-for-creating-a-clickhouse-cluster-from-scratch-4c6638fb5a06
https://oneuptime.com/blog/post/2026-03-31-clickhouse-what-is-a-dictionary/view
https://oneuptime.com/blog/post/2026-03-31-clickhouse-keeper-3-node-cluster/view
https://www.conduktor.io/kafka/kafka-topic-configuration-min-insync-replicas
https://docs.confluent.io/kafka/design/replication.html
https://hub.docker.com/r/apache/kafka
https://saiparvathaneni.medium.com/kafka-multi-node-cluster-simplified-6cea0ba5f1dd
https://oneuptime.com/blog/post/2026-01-30-kafka-controller-quorum/view
https://github.com/pmacct/pmacct/blob/master/CONFIG-KEYS
again, chatgpt gratis